
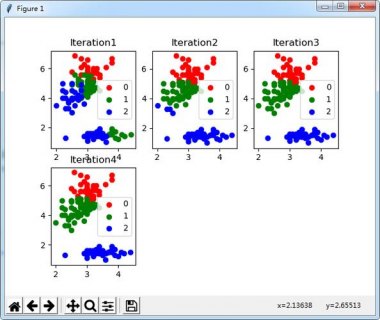
k-means聚类算法是一种常用的无监督学习算法,用于将数据集划分为k个不同的簇,它通过迭代地移动簇的质心来最小化簇内样本点之间的距离之和,下面是对k-means聚类算法的详细解释:
1. 初始化:选择k个初始质心,可以是随机选择或使用其他启发式方法,每个数据点都被分配到离其最近的质心所代表的簇中。

2. 分配数据点:计算每个数据点与所有质心之间的距离,并将其分配到距离最近的质心所代表的簇中。
3. 更新质心:对于每个簇,计算其中所有数据点的平均值,并将该平均值作为新的质心。
4. 重复步骤2和步骤3:重复执行步骤2和步骤3,直到满足停止条件为止,停止条件可以是在达到最大迭代次数后,或者当质心不再发生变化时。
5. 结果评估:根据聚类结果进行评估,可以使用内部指标(如轮廓系数)或外部指标(如调整兰德指数)来衡量聚类的质量。

下面是一个示例代码,演示了如何在Python中实现k-means聚类算法:
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 生成随机数据集
data, labels = make_blobs(n_samples=300, centers=4, random_state=42)
# 创建KMeans对象并拟合数据
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(data)
# 获取聚类结果和质心坐标
labels_pred = kmeans.predict(data)
centroids = kmeans.cluster_centers_
# 打印聚类结果和质心坐标
print("Cluster labels:", labels_pred)
print("Centroid coordinates:", centroids)
在上述代码中,我们使用了`sklearn`库中的`KMeans`类来实现k-means聚类算法,我们生成了一个包含300个样本、4个簇的随机数据集,我们创建了一个`KMeans`对象,指定要分成的簇数为4,并使用`fit`方法拟合数据,我们使用`predict`方法获取每个样本点的预测标签,以及使用`cluster_centers_`属性获取质心的坐标。
现在让我们进入相关问题与解答的环节:
问题1:如何选择合适的簇数k?
答:选择合适的簇数k是k-means聚类算法的一个重要问题,一种常见的方法是使用肘部法则(Elbow Method),通过绘制不同簇数下的SSE(误差平方和)曲线来找到最佳的簇数,当增加簇数时,SSE会逐渐减小,但在某个点之后,SSE的下降速度会变缓,这个点通常被称为"肘部",选择该点之前的簇数作为最佳簇数,还可以使用轮廓系数等内部指标来评估不同簇数下的聚类质量。
问题2:如何处理具有噪声的数据?
答:k-means聚类算法对噪声敏感,因为噪声可能会影响质心的计算和簇的划分,为了处理具有噪声的数据,可以采取以下几种方法:可以尝试多次运行k-means算法并取平均值,以减少随机性的影响,可以考虑使用软聚类方法(如k-medoids或DBSCAN),它们对噪声更加鲁棒,还可以尝试使用更鲁棒的距离度量方法(如欧氏距离的加权版本),以减少噪声对距离计算的影响,预处理数据也是一个重要的步骤,例如去除异常值或使用滤波器来平滑数据。
 微信扫一扫打赏
微信扫一扫打赏


折叠式设计巧妙,轻便携带,是提升办公与学习体验的贴心小物,它不仅自由调节角度,缓解颈椎压力,还兼顾散热,实用与美观兼备,确实是一款适合现代打工人与学生党的电脑支
平面设计笔记本,重性能更重便携,精选配置推荐,助你创意无限,工作效率加倍!
在众多笔记本电脑电池中,锂电池以其轻便、环保且无记忆效应的特性脱颖而出,尤其是高容量、长续航的锂离子电池,是追求移动办公和高效生活的理想选择。
JavaScript通过不依赖具体类型来实现多态,巧妙地利用了鸭子类型和原型链,让同一个方法在不同对象上有不同表现,这正是其魅力所在。
下载即得ISO映像,轻松操作至U盘或硬盘,安装Win10如此简单!