

在PL/SQL中,可以使用ROW_NUMBER()窗口函数结合DELETE语句删除重复数据。首先为每个重复的记录分配一个唯一的行号,然后删除行号大于1的记录,从而保留每个重复记录中的第一条记录。,,``sql,DELETE FROM 表名,WHERE ROWID IN (, SELECT ROWID, FROM (, SELECT ROW_NUMBER() OVER (PARTITION BY 列名1, 列名2, ... ORDER BY 排序列) AS row_num, ROWID, FROM 表名, ), WHERE row_num > 1,);,``在PL/SQL中,删除重复数据通常需要以下步骤:
1、确定重复数据:你需要确定哪些数据是重复的,这通常涉及到查找具有相同列值的行。
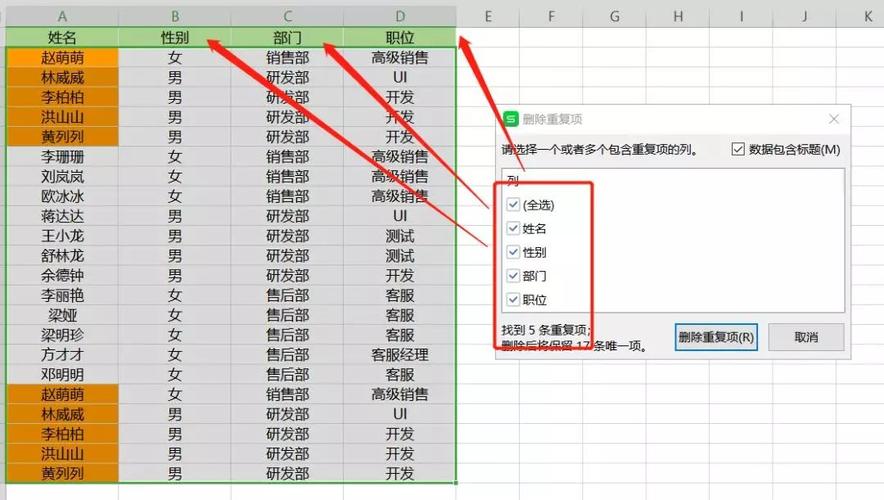
2、选择要保留的数据:一旦你确定了哪些数据是重复的,你需要决定保留哪个版本,这可能是基于某个特定列的最大或最小值,或者是随机选择。
3、删除重复数据:你需要编写一个SQL语句来删除重复的数据。
以下是一个简单的例子,假设我们有一个名为employees的表,它有id, name, email和salary列,我们希望删除email列中的重复数据。
DELETE FROM employees WHERE id NOT IN ( SELECT MIN(id) FROM employees GROUP BY email );
在这个例子中,我们首先找出每个email的最小id,然后删除所有不在这个列表中的行,这样,我们就保留了每个email的最小id的行,删除了其他所有的重复行。
相关问题与解答:
Q1: 如果我想删除所有重复的数据,而不仅仅是保留最小或最大ID的行,我应该怎么办?
A1: 你可以使用ROW_NUMBER()函数为每个分组的行分配一个唯一的数字,然后删除所有row_number大于1的行。

DELETE FROM employees
WHERE id NOT IN (
SELECT id
FROM (
SELECT id, ROW_NUMBER() OVER (PARTITION BY email ORDER BY id) as row_number
FROM employees
)
WHERE row_number = 1
);
Q2: 我可以在删除重复数据后,立即看到结果吗?
A2: 是的,你可以在删除操作完成后立即查询表以查看结果,请注意,如果你的表非常大,这个操作可能需要一些时间来完成。









还没有评论,来说两句吧...