
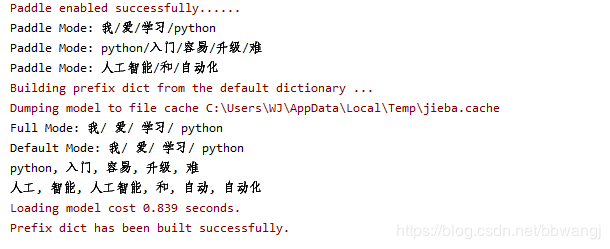
正向最大匹配算法(Maximum Forward Matching,简称MFM)是一种常用的中文分词方法,它的基本思想是:从左到右扫描文本,每次取尽可能长的词语进行匹配,具体步骤如下:
1. 初始化:将待分词的文本作为输入,首先对文本进行预处理,包括去除标点符号、数字等无关字符,将文本转换为小写等。

2. 扫描文本:从左到右扫描文本,每次取一个汉字作为当前词的起始字。
3. 匹配词语:在词典中查找以当前词的起始字开头的最长词语,如果找到,则将该词语作为一个词条输出;如果没有找到,则将当前词的起始字作为一个单字词条输出。
4. 更新状态:将当前词的起始字向右移动一位,继续扫描文本,重复步骤2和3,直到扫描完整个文本。
5. 输出结果:将分词结果输出。

正向最大匹配算法的优点是可以较好地处理未登录词和歧义消解问题,由于它每次都取尽可能长的词语进行匹配,因此对于一些生僻词或者新词,即使它们不在词典中,也可以被正确地切分出来,正向最大匹配算法还可以通过调整匹配长度来平衡精确率和召回率,从而在一定程度上解决歧义问题。
正向最大匹配算法也存在一些缺点,它需要预先构建一个包含大量词语的词典,这在实际应用中可能会遇到困难,正向最大匹配算法对于长句子的处理能力较弱,容易出现切分错误,正向最大匹配算法无法处理多字词组,如“中华人民共和国”这样的词语会被错误地切分为“中华/人民共和国”。
为了解决这些问题,可以采用一些改进的方法,如基于统计的分词方法、基于规则的分词方法等,这些方法在一定程度上可以提高分词的准确性和效率。
相关问题与解答:
1. 正向最大匹配算法如何处理未登录词?
答:正向最大匹配算法通过取尽可能长的词语进行匹配,可以较好地处理未登录词,当遇到一个未登录词时,它可以将其作为一个单字词条输出,从而实现正确的切分。
2. 正向最大匹配算法如何平衡精确率和召回率?
答:正向最大匹配算法可以通过调整匹配长度来平衡精确率和召回率,当匹配长度较短时,可以提高精确率但降低召回率;当匹配长度较长时,可以提高召回率但降低精确率,通过实验选择合适的匹配长度,可以在保证分词准确性的同时提高召回率。
 微信扫一扫打赏
微信扫一扫打赏


探索双交火显卡的thinkpad,性能卓越,适合追求极致图形体验的用户,其售价因配置、市场等因素而异,但无疑是一款值得拥有的高效能装备。
遇到笔记本无法播放碟片别担心,先确认光驱类型与碟片格式是否匹配,再试试清洗或更换光驱,软件问题也不容忽视哦!
追求流畅游戏直播,关键是平衡CPU与显卡性能,确保至少i5处理器和GTX1660Ti显卡,内存不低于16GB,享受高清流畅体验!
滴滴空驶费,是对司机时间与油费的补偿,体现了对劳动者尊重,也是平台公平正义的体现。
遇到wifi密码正确却连不上网络的情况,可能是信号问题或是网络设置的小故障,别担心,尝试重启路由器或调整电脑的网络设置,通常能轻松解决问题。