
在Python中,正则表达式是一种强大的工具,用于处理字符串,它可以帮助我们匹配、查找、替换和分割字符串,在正则表达式中,有几种模式可供选择,其中之一就是ASCII模式,本文将详细介绍Python中使用正则表达式的ASCII模式。
1. ASCII模式简介

ASCII模式是正则表达式的一种模式,它只匹配ASCII字符,ASCII字符是0-127之间的数字,包括字母、数字和标点符号等,在ASCII模式下,正则表达式引擎会忽略非ASCII字符,只关注ASCII字符。
2. 使用ASCII模式
在Python中,我们可以使用`re`模块来处理正则表达式,要使用ASCII模式,我们需要在正则表达式的开头添加一个`(?ascii)`标志。
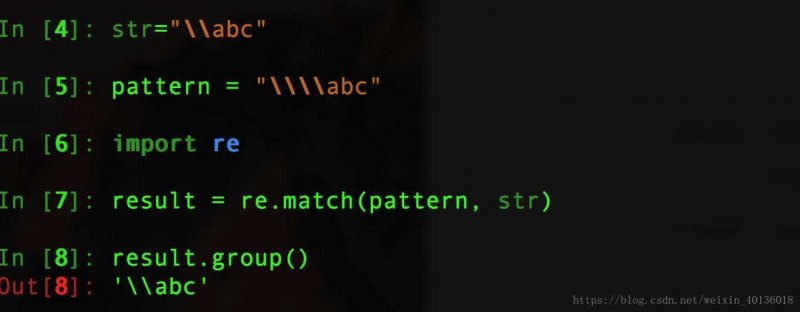
import re pattern = r'(?ascii)hello' text = '你好,世界!hello' match = re.search(pattern, text) print(match.group()) # 输出:hello
在上面的例子中,我们使用了`(?ascii)`标志来指定ASCII模式,我们创建了一个正则表达式模式`hello`,并尝试在文本`你好,世界!hello`中搜索该模式,由于我们在ASCII模式下运行正则表达式,所以引擎会忽略非ASCII字符(如中文字符),只关注ASCII字符(如英文字符),我们得到了匹配结果`hello`。

3. ASCII模式的应用场景
ASCII模式在某些场景下非常有用,例如:
- 当我们需要处理纯文本数据时,可以使用ASCII模式来确保只匹配ASCII字符,这可以避免因非ASCII字符引起的问题。
- 当我们需要对文本进行简单的查找和替换操作时,可以使用ASCII模式来简化正则表达式,这样可以减少错误的可能性,提高代码的可读性。
4. ASCII模式的限制
虽然ASCII模式在某些场景下非常有用,但它也有一些限制:
- ASCII模式不能处理Unicode字符,如果文本中包含Unicode字符,我们需要使用其他模式(如Unicode模式)来处理。
- ASCII模式不能处理多行文本,如果需要处理多行文本,我们需要使用其他方法(如多行模式)来实现。
5. 相关技术介绍
除了ASCII模式之外,Python中的正则表达式还支持其他几种模式,如:
- `re.A`:默认模式,匹配任何字符(包括Unicode字符)。
- `re.L`:做本地化识别(locale-aware)匹配(包括多字节字符),这个标志影响 \w, W, \b, \B.等元字符。
- `re.M`:多行匹配,影响 ^ 和 $。
- `re.S`:使 . 匹配包括换行在内的所有字符。
- `re.U`:根据Unicode字符集解析字符,这个标志影响 w, \W, \b, \B. 以及 \s 和 \S.
- `re.X`:该标志通过给予你更灵活的格式以便你将空白视为特殊字符。
- `re.I`:使匹配对大小写不敏感。
- `re.L`:做本地化识别(locale-aware)匹配(包括多字节字符),这个标志影响 \w, \W, b, \B. 等元字符。
- `re.U`:根据Unicode字符集解析字符,这个标志影响 \w, \W, \b, \B. 以及 \s 和 S.
6. 总结
本文详细介绍了Python中使用正则表达式的ASCII模式,ASCII模式是一种只匹配ASCII字符的模式,它可以帮助我们处理纯文本数据和进行简单的查找和替换操作,ASCII模式也有一些限制,如不能处理Unicode字符和多行文本,在使用正则表达式时,我们需要根据实际需求选择合适的模式。
 微信扫一扫打赏
微信扫一扫打赏







简洁而不失强大的统计脚本,轻松处理数据,展现了编程的魅力,独到见解:期待未来加入可视化功能,让数据分析更直观有趣!
1050ti显卡搭配1080p显示器最佳,性价比高,体验流畅,若偏好更高分辨率,2k显示器也能驾驭,但要注意选择品牌质量,避免拖影现象,享受细腻画质。
越权漏洞,犹如系统内的隐秘裂缝,让安全防线瞬间崩塌,它提醒我们,权限控制不仅是对功能的限制,更是对用户隐私和系统稳定的守护。
精挑细选笔记本,配置排名前十引领潮流,选购必看!
吾空游戏本实力派,性能卓越散热佳,高清大屏视觉盛宴,轻薄设计携带方便,性价比之选!